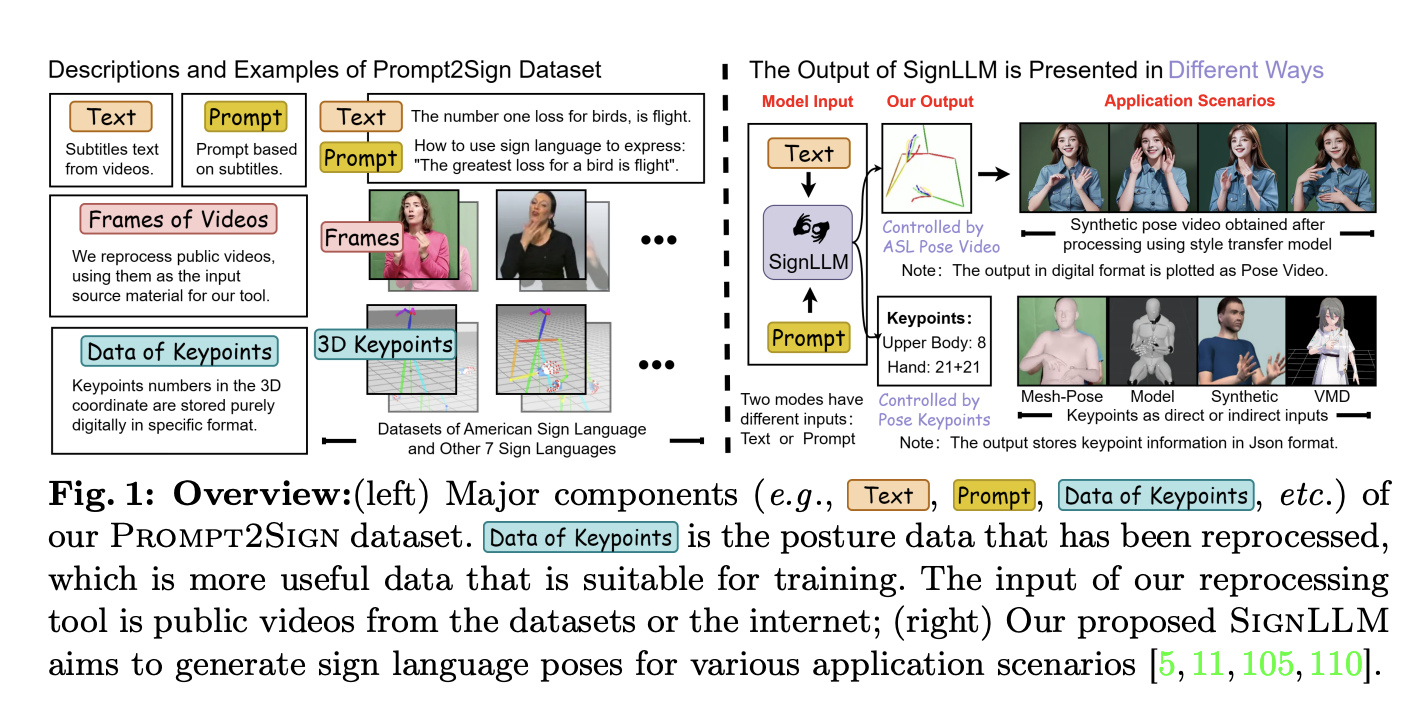
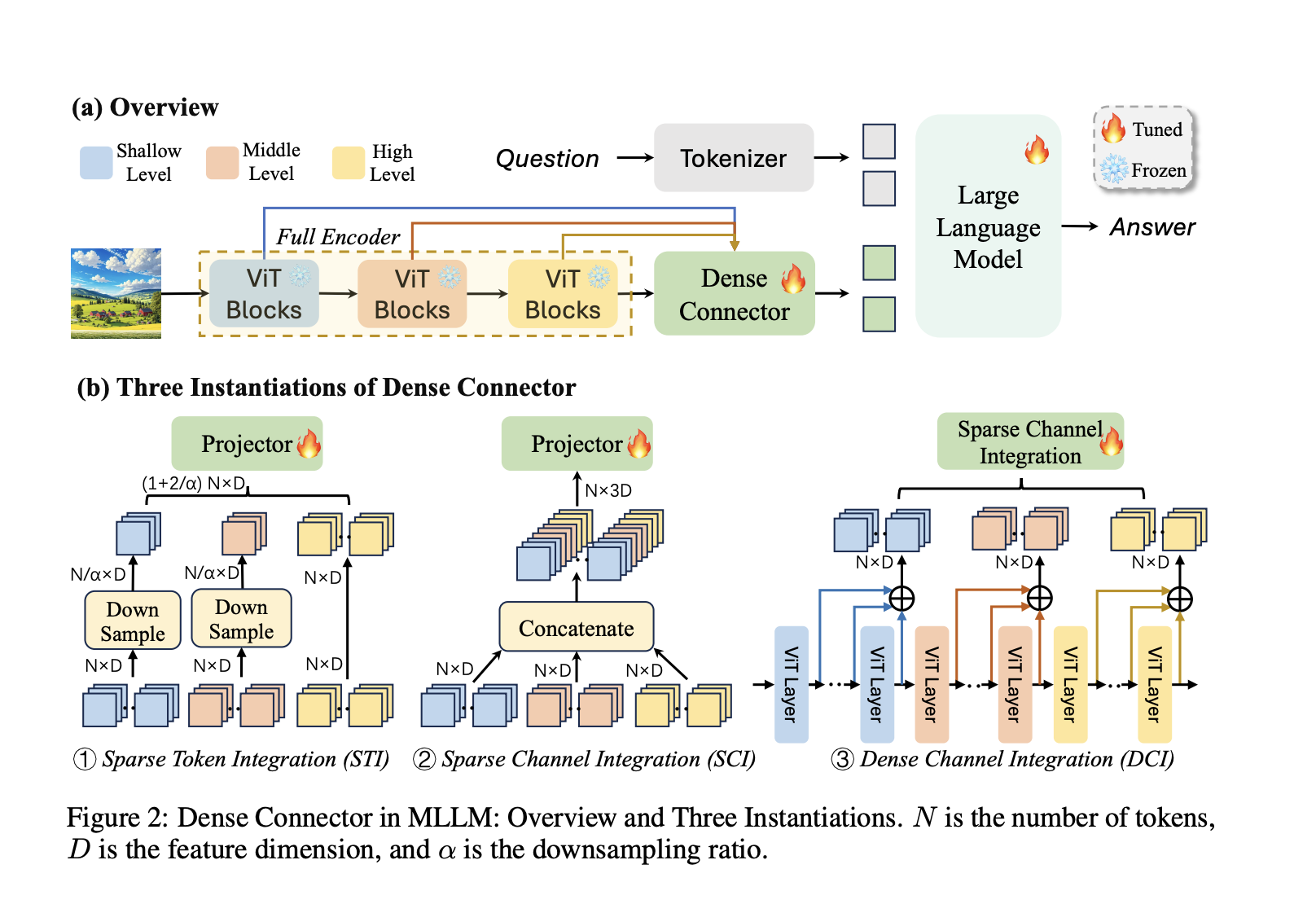
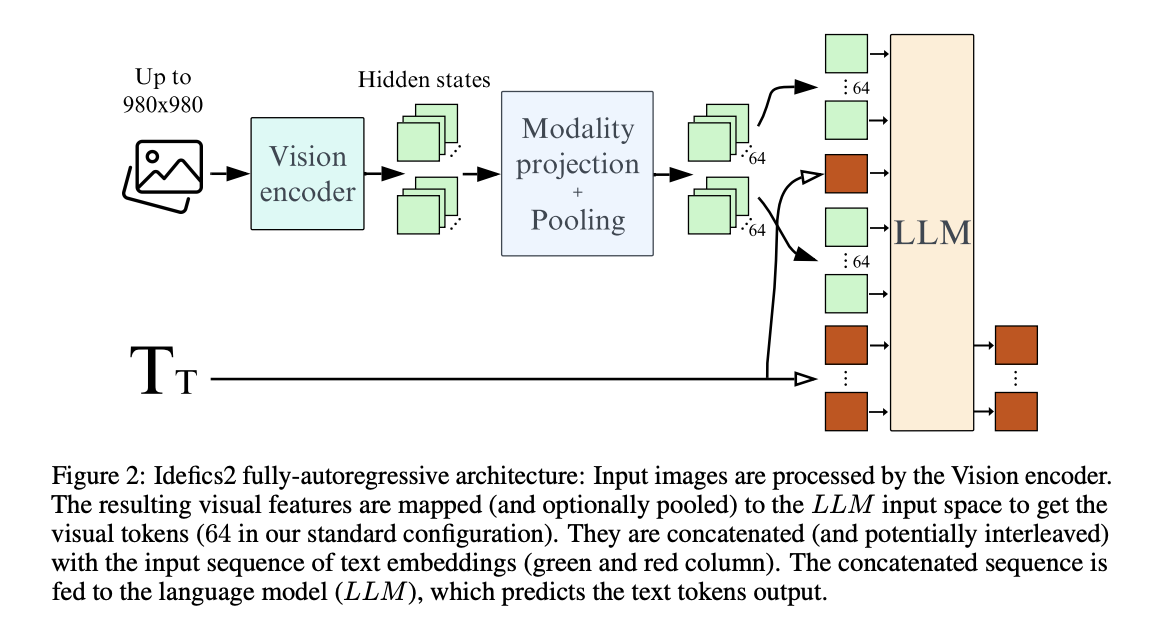
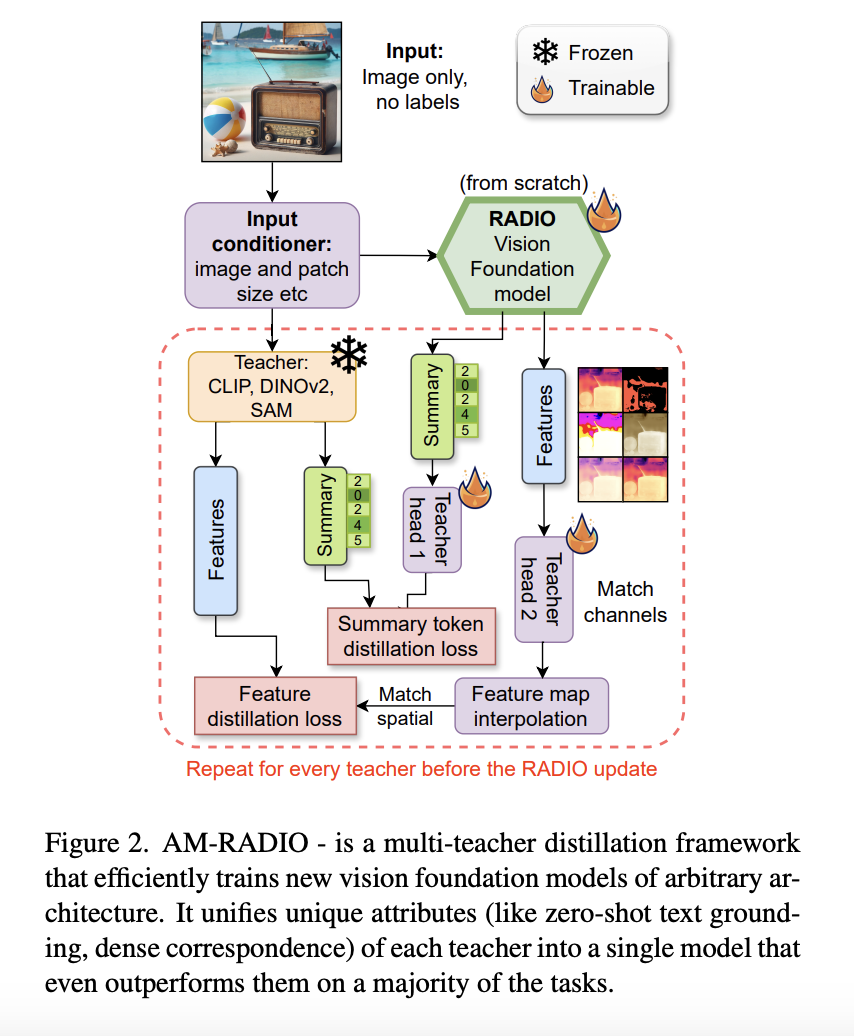
The primary goal of Sign Language Production (SLP) is to create sign avatars that resemble humans using text inputs. The standard procedure for SLP methods based on deep learning involves several steps. First, the text is translated into gloss, a language that represents postures and gestures. This gloss is then used to generate a video…